如今,我们生活在一个大规模语言模型(LLM)的使用决定公司竞争力的时代。然而,基于云的人工智能服务仍然存在数据隐私和成本问题。
在本文中,我们将讨论如何通过引入日语支持来解决这些问题。如何在本地环境中利用开源法学硕士并对其进行定制以满足您公司的需求我会解释一下。具体来说,我们将解释模型微调方法和利用外部知识构建 RAG(检索增强生成)的过程以及实际步骤。

本文内容在上面的GPT主播室以简单易懂的音频进行讲解。
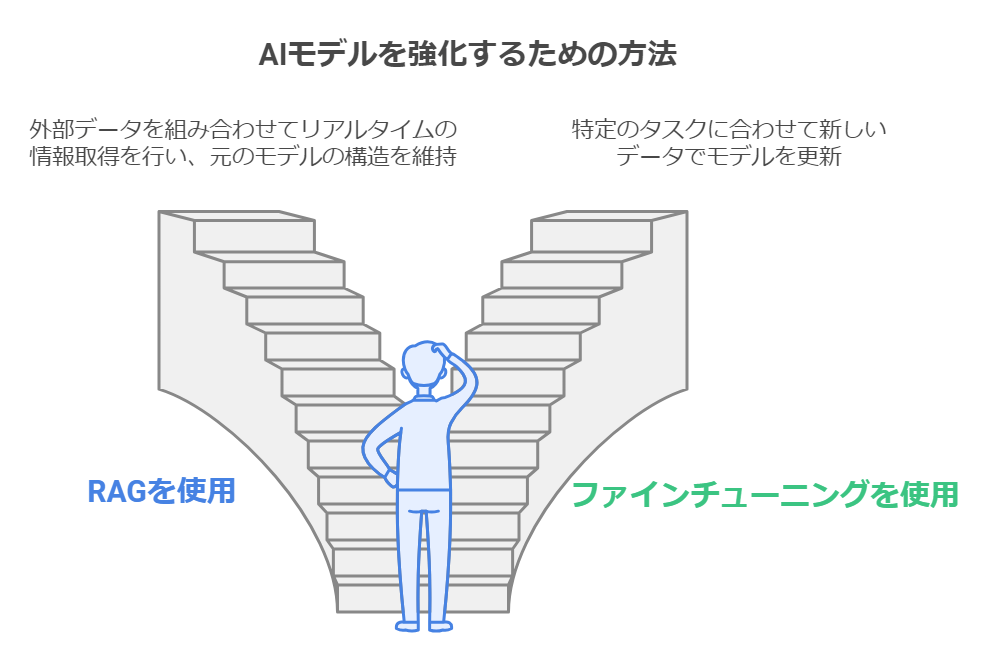
首先,请看一下RAG和微调之间的区别。
RAG(检索-增强生成)
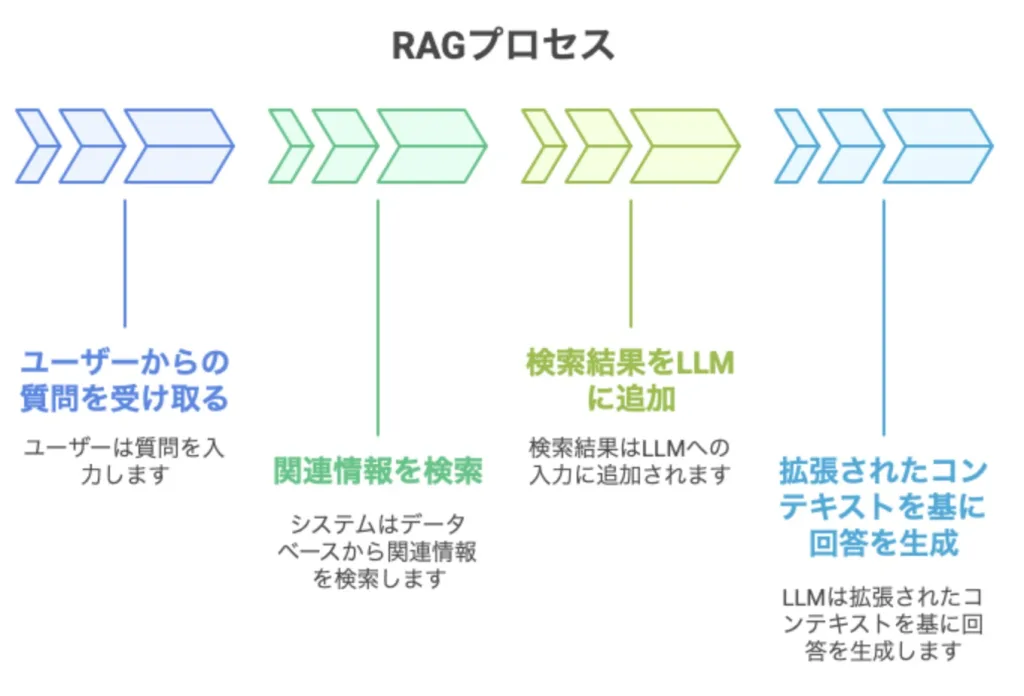
什么是RAG?一种将“信息搜索”功能融入AI答案生成过程的方法是。为了超越传统法学硕士知识的限制,我们从外部数据库中实时搜索相关信息来回答问题,并根据这些信息生成答案。
例如,在回答“我们的新产品X有什么特点?”这个问题时,您可以从内部文档中搜索有关产品X的信息,并根据该信息生成答案。重要的一点是模型本身没有改变,而是使用外部知识作为“上下文”。
微调
一种通过添加新数据来重新训练现有模型以使其更适合特定任务或用途的方法。更新模型本身我会。
一般来说,RAG相对容易初始化和操作这尤其适合需要获取最新信息或需要频繁更新数据的情况。另一方面,微调需要时间和精力来进行初始数据准备和学习。但是,当特定任务需要高精度时,它很有用。
本地LLM微调和RAG建设的好处

对于客户信件和文档创建很有用!
通过微调当地的LLM,针对特定业务需求的定制使能够。特定业务需求的示例包括客户服务、文档创建和翻译。
通过构建一个能够理解日语的独特细微差别以及行业特定术语和数据的模型,我们能够在各种业务情况下提供高质量的服务。
构建 RAG 可以填补知识的缺乏
通过构建 RAG,通过利用外部知识(例如过去的客户互动和对话历史记录)来提高生成式人工智能的性能你可以。利用外部知识可以填补特定领域或主题的知识空白,从而大大提高运营效率。
使用本地LLM的优势
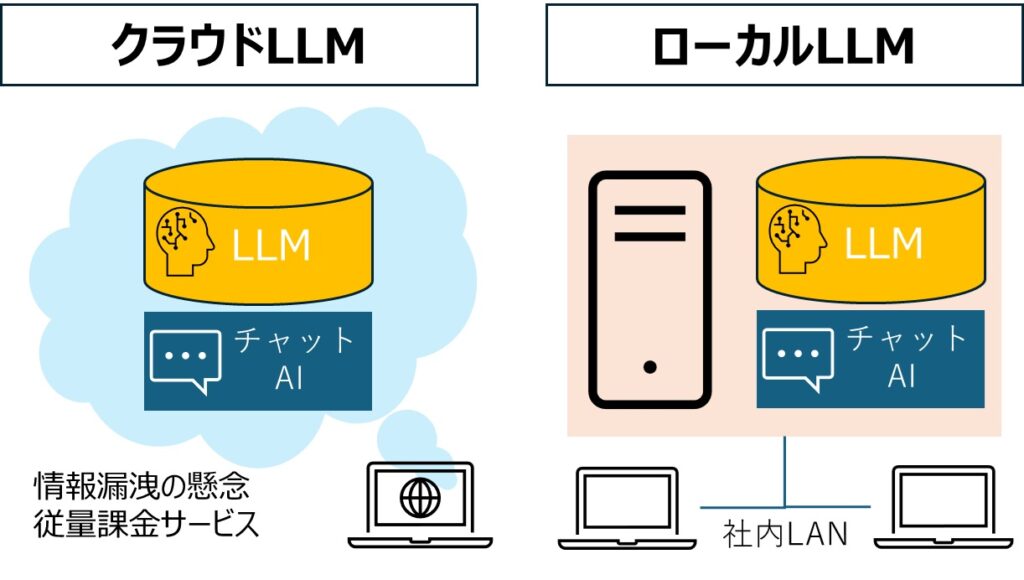
1. 提高数据隐私和安全性
通过在本地运行 LLM,敏感数据不会发送到外部服务器。从而显着降低信息泄露的风险,尤其是处理个人信息和商业秘密的企业您可以放心使用。
2. 业务定制
本地法学硕士的主要优势是能够微调模型以适应贵公司独特的业务内容和数据。
例如,学习公司内部使用的技术术语和行业特定表达方式这可以实现一般人工智能服务无法实现的高度准确的业务支持。这极大地提高了文档创建和信息检索等任务的效率。
3.离线环境下使用
由于不需要互联网连接,因此即使在无法保证稳定通信的情况下也可以使用LLM。例如,可用于工厂、建筑工地等没有互联网环境的地方是。
4.降低成本
可以降低云服务使用费、API调用成本等运行成本。尤其是LLM大规模应用时,其成本效益是显着的。
本地法学硕士用例

制造业
它可用于在产品开发中产生想法并自动创建手册。通过了解以往的产品信息和技术文档,您可以为适合您公司的新产品产生创意和设计开发。
医疗领域
自动创建电子病历和医学影像诊断将用于支持等。通过将医生的语音数据实时转换为文本并自动输入电子病历,减轻医生的行政工作负担。
教育领域
提供个性化优化的学习体验并自动创建教材它用于类似的事情。根据每个学生的学习进度和理解水平,提供最合适的教材和问题,从而实现适应性学习。
金融领域
自动欺诈交易检测和客户响应它用于此类事情。它可以从过去的交易数据中学习欺诈交易模式并实时检测欺诈行为。
为企业提供本地法学硕士服务
如果您使用 LM Studio 或 Ollama,则可以在您的个人 PC 上运行本地 LLM。然而,如果您想建立一个利用您公司数据的本地法学硕士,那么 RAG 的功能就不足了。
为企业推荐的本地法学硕士服务如果您有兴趣,请往下看。
微调本地LLM的步骤

第一步:准备环境
首先,从 Python 和所需的库开始(例如transformers,langchain,chromadbETC。)。它可以在Google Colaboratory或本地环境中执行。
另外,在 Hugging Face 上注册并访问该模型。骆驼模型作为门控模型提供,因此您需要申请使用权。
第二步:模型选择和微调
接下来是模型选择和微调。
选型
日语兼容开源法学硕士从中选择合适的型号。例如,Meta 的 Llama 和 Google 的 Gemma 都是候选者。
微调
针对特定任务微调所选模型。通常使用LoRA(低秩适应)等方法。
使用下面的 Python 代码执行微调。该代码使用Meta的Llama 3(8B参数版本)作为基础模型,并使用LoRA方法进行高效的微调。
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, PeftModel
from trl import SFTTrainer
model_name = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# LoRA設定
lora_config = LoraConfig(r=64, lora_alpha=16, lora_dropout=0.1)
trainer = SFTTrainer(model=model, tokenizer=tokenizer, peft_config=lora_config)
trainer.train()
步骤3:RAG构建
RAG是一种结合信息检索和生成的方法。使用以下步骤构建 RAG。
准备数据库
在RAG中,为了从外部数据库获取信息,色度数据库使用向量存储,例如数据库存储相关文档和信息。
信息搜索功能的实现
浪链我们将实现一个功能来搜索数据库以获取与用户问题相关的信息。
与生成模型集成
配置生成模型以根据您检索到的信息生成答案。下面是一个例子。
from langchain.chains import RetrievalQA
from langchain.vectorstores import Chroma
# ベクトルストアから情報取得
vectorstore = Chroma.from_documents(texts, embeddings)
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# 質問応答
response = qa_chain.run("データアナリティクスラボ株式会社について教えてください。")
第 4 步:测试和评估
测试搭建的RAG系统是否正常工作。验证各种问题是否按预期得到回答,并根据需要调整模型和数据库。
微调本地 LLM 以构建 RAG:总结

微调本地 LLM 并使用日语兼容的开源 LLM 构建 RAG 是构建具有高级自然语言处理功能的您自己的系统的强大方法。
这个过程包括从环境设置、模型选择、微调和RAG构建开始的一系列步骤。通过微调您当地的 LLM 并构建 RAG,您可以创建适合您的需求和业务需求的可定制 AI 系统。